
好,我们今天来聊一个挺有意思的事情。
2026年这个时间点,几乎所有主流的前沿大模型都在宣传自己「支持至少一百万token的上下文窗口」。听起来很美好,对吧?但实际情况是,真正能把这一百万token用好的模型,基本没有。
大家可以看一下MRCR v2这个榜单,它是专门测多参考检索能力的。目前跑得最好的是GPT-5.5,也就74分。其他的呢?比如Claude Opus 4.7,只有32.2分,差距还挺大的。
就是说,虽然大家都在卷上下文长度,但「长」和「用得好」完全是两回事。
为什么大家都卡在一百万?
这个地方我们要稍微展开一下。为什么前沿的几个大厂都差不多停在一百万token这个位置?
原因其实从2017年Transformer论文出来那天起就没变过——注意力机制的计算成本是和上下文长度的平方成正比的。
简单翻译一下:你输入翻倍,计算量要变成原来的四倍。
所以大家平时听到的那些东西,什么RAG、Agent拆分、混合架构……实际上都是在绕这个事情。本质上都是在做取舍——既然硬算算不动,那就想办法不算那么多。
Subquadratic:我要把这道坎直接拆了
好,现在主角登场。
Subquadratic是一家迈阿密的初创公司。本周二他们发布了第一个模型,直接甩出了一个1200万token的上下文窗口。而且他们还说,5000万token的版本也快了。
这家公司团队里有11个博士,他们提出的架构叫做SSA——Subquadratic Selective Attention(次二次选择性注意力)。按他们的说法,这个架构在计算和内存两方面都是随上下文长度线性增长的。
几个他们自己放出来的数字:
- 一百万token的时候,比传统的dense attention快 52倍
- 1200万token的大海捞针测试,准确率 92.1%(目前没有哪个前沿模型能跑到这么长)
- MRCR v2 跑到 83分,比OpenAI高9分
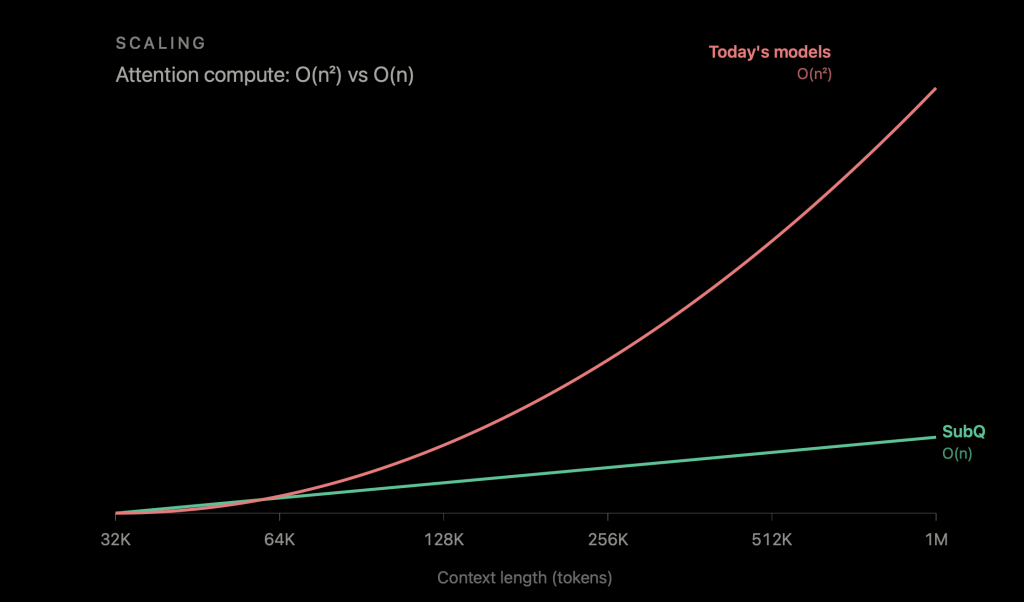
SSA这个架构,在一百万token时速度是dense attention的52倍,1200万token大海捞针拿到92.1%,MRCR v2 83分——比OpenAI高9分。
当然了,这些数字听起来是挺唬人的。而且Subquadratic也不是第一个想解决这个问题的公司。但是这次他们放出来的benchmark确实有点东西——SWE-bench拿了82.4%,比Anthropic上一代Opus 4.6的81.42%还要高那么一点,也超过了Google的Gemini 3.1 Pro的80.6%。而且成本要低得多。
这个模型现在是通过API开放的,窗口直接就是1200万token。配套还有一个编程Agent叫SubQ Code,一个深度研究工具叫SubQ Search。
在SSA之前大家都试过什么
好,这一块我们稍微往回看一下历史。
注意力机制的平方复杂度不是什么新问题,SSA也不是第一个想解决这个问题的方案。这条研究线几乎可以追溯到Transformer论文本身,而且这些年下来大家基本上都在重复一个模式:
每一种新方法,都在牺牲某个必要的属性去换另一个属性,但是没有一个能在前沿规模上真正替代掉dense attention。
我们一个一个看。
第一类是固定模式的稀疏注意力。比如Longformer,它让每个token只关注一个滑动窗口范围内的其他token,这样就能做到线性复杂度。这个思路在相关信息就在附近的时候管用,信息一旦隔得远,就不行了。
第二类是状态空间模型,比如Mamba、Mamba-2、RWKV、RetNet这些。它们的思路是:不要比对所有token两两之间的关系,而是用一个循环状态把前面看过的东西都压缩进去。
但问题是,压缩是有损的。英伟达在8B规模上做过一个研究,纯Mamba-2在MMLU和电话簿查找这种任务上,是明显落后Transformer的。只有把attention加回来,差距才会缩小。
第三类是混合架构,Jamba、Kimi Linear、Qwen3-Next、英伟达的Nemotron v3都是这个路子。大部分层用便宜的方法做,保留少数几层dense attention用来做检索。
这个思路看起来很聪明,但是账算下来其实没那么划算。一个在32K token的时候便宜三倍的混合模型,到了1000万token的时候,还是只便宜三倍。为什么?因为它保留的那几层dense attention,还在老老实实做O(n²)的计算。
最近一类的思路就有点不一样了。大家不再是去修补固定模式,也不再去压缩状态,而是让模型自己学着去选哪些位置值得看。
比如说DeepSeek的Native Sparse Attention,去年还拿了ACL 2025的最佳论文。它的后续版本叫DSA(DeepSeek Sparse Attention),已经在DeepSeek V3.2-Exp里上线了。DSA的做法是:用一个"闪电索引器"挑出一小部分key,然后attention只在这些选出来的key上做,这部分是真的稀疏。
但是这里有个坑:那个负责挑选的索引器,自己还是要把每个query和每个key都打一遍分。所以"选"这一步本身还是平方复杂度。
Subquadratic的CTO Alex Whedon是这么和The New Stack说的:
「所谓稀疏注意力,就是说你不用像传统Transformer那样——有1000个词,就要看这1000个词之间所有可能的1000²种组合。你会意识到其实只有一小部分是真正重要的,那就只处理那一小部分就行了。」
SSA到底做对了什么
好,重点来了。
SSA的卖点是——DSA想做的事情我都做了,但是没掉进索引器那个坑。
它的选择是基于内容的:对于某个query,模型会根据query和key里真正的内容来决定哪些位置重要。最关键的一点是:选择这个动作本身,不会退化成平方复杂度。
Whedon是这么解释的:
「对于prompt A来说,第一个词和第六个词之间关系可能很重要。对于prompt B,可能就是第二个和第三个重要。每次输入都不一样。」
他还说了一句挺关键的话:混合架构给的是标量级的好处——你省3倍,就永远省3倍;而一个真正的次二次机制,给的是scaling law级的好处——长度越长,优势越大。
从他们自己的数据看:
- 128K token时快 7.2倍
- 1M token时快 52.2倍
这个差距是会随长度继续拉大的。
Benchmark我们过一遍
好,我们来看几个具体的数字。
RULER 128K:SubQ拿了97.1,Opus 4.6是94.8。
MRCR v2:SubQ和其他前沿模型的差距,比其他前沿模型彼此之间的差距还要大。这个有点夸张了。
SWE-Bench Verified:SubQ是82.4%,略高于Opus 4.6的81.4%,也高于Gemini 3.1 Pro的80.6%。
1200万token大海捞针:92.1%。这个长度目前没有任何一个前沿模型能跑。
当然了,这里也有几个需要注意的地方:
- 根据他们的技术报告,每个模型只跑了一次,因为推理成本太高
- SWE-Bench那个差距,他们自己也承认,「一半功劳是harness而不是模型本身」
- SubQ这个模型,用Whedon自己的话说,「比那几个大厂的模型小得多」
所以这些数字看着很漂亮,但也别把它们看成盖棺定论。
现在他们到底放出来了什么
Subquadratic现在发布的是两个beta产品:
- API——带完整的1200万token上下文
- SubQ Code——一个基于同一模型的命令行Agent
运行环境用的是neocloud(新兴的GPU云),不是那几个hyperscaler。CEO Justin Dangel的原话是——「那几个太贵了。」
模型权重目前不开源,但是他们计划提供训练工具,让企业可以自己做后训练。5000万token上下文的目标,定在今年Q4。
最后说一个扫兴的事情
好,我们要保持一点冷静。
大家还记得Magic.dev吗?2024年8月,他们宣布了一个1亿token上下文的模型,号称比同行高效1000倍。就靠这个故事,他们融了超过5亿美金。
到2026年初,除了Magic自己,外面基本看不到LTM-2-mini被实际使用的证据。
融资情况
Subquadratic到目前为止融了2900万美金,估值5亿美金。投资人里包括前软银愿景基金合伙人Javier Villamizar,以及Tinder联合创始人Justin Mateen。
这家公司以前叫Aldea,之前做的是语音模型,后来转型到现在这个方向。
一句话总结:技术上这个故事是真实的,值得期待。但是这条赛道过去的记录——就是另一回事了。