
这两天 Google AI 发了一篇挺技术向的博文,讲的是 Gemma 4 的一个新能力:Multi-Token Prediction,简称 MTP。
如果只看标题,可能会觉得这是一个很底层的模型优化。
但我觉得它对开发者挺重要。
因为现在很多人跑本地模型,或者把模型接进自己的产品里,最头疼的不是模型不会回答,而是回答太慢。
用户在聊天框里等,开发者在终端里等,agent 在一步一步规划的时候也在等。模型越大,等得越明显。
所以 Google 这次想解决的,不是“模型再聪明一点”的问题,而是“同样的模型,能不能更快吐字”的问题。
Gemma 4 已经不只是实验模型了
Google 在文章里提到,Gemma 4 发布才几周,下载量已经超过 6000 万。
这个数字说明一件事:Gemma 这条线已经不只是 Google 用来展示技术的 open model,而是真的被开发者拿去跑在工作站、移动设备和云端。
Gemma 4 本身有几个关键词:开放模型、开发者友好、本地和边缘设备可用。
也就是说,它不是只服务大型云推理的模型。它还想进入个人电脑、消费级 GPU、手机、边缘设备这些地方。
那问题就来了。
这些设备的算力和显存带宽,跟数据中心不是一个量级。模型稍微大一点,生成速度就容易卡。
所以 Gemma 4 这次的重点不是堆更大参数,而是提高推理效率。
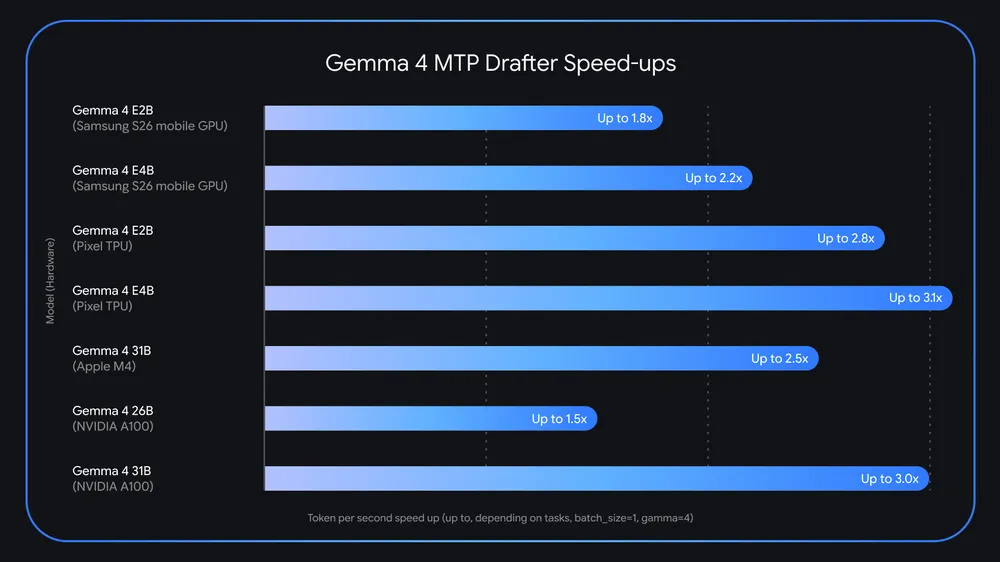
Google 给 Gemma 4 家族发布了 MTP drafters。按照 Google 的说法,在不降低输出质量和推理逻辑的前提下,速度最高可以提升到 3 倍。
为什么大模型生成会慢?
好,我们先把问题讲简单一点。
大语言模型生成文本,通常是一个 token 一个 token 往外吐。
比如它要生成一句话,不是一次把整句话都写出来,而是先算第一个 token,再根据前面的结果算第二个,再算第三个。这个过程叫 autoregressive generation。
这个方式很稳,但有一个问题:慢。
尤其是在大模型上,每生成一个 token,都要把大量参数从显存搬到计算单元里。很多时候瓶颈不在算力本身,而在内存带宽。
就是说,GPU 不是完全算不过来,而是大量时间花在“搬模型参数”上。
这就会导致一个很尴尬的情况:计算资源没有被充分利用,但用户依然在等。
尤其是消费级硬件,本地跑模型时这个感觉会更明显。
MTP 的思路:先让小模型打草稿,再让大模型判卷
MTP 背后的核心思想是 speculative decoding。
这个词直接翻译叫“推测解码”,但我更愿意把它理解成:先打草稿,再验证。
传统方式是大模型一步一步生成。MTP 的方式是:旁边放一个更轻量的 drafter,也就是草稿模型,让它先猜接下来几个 token。
然后主模型不是完全相信它,而是一次性验证这些候选 token。
如果主模型认可,就直接接受一串 token。这样原来需要一步一步生成的内容,现在可以在一次前向计算里推进好几步。
如果主模型不认可,也不会乱输出。它会给出正确 token,然后 drafter 再从这个新位置继续预测。
这个机制的关键点是:最终拍板的还是主模型。
所以从产品体验上看,用户拿到的质量和推理能力还是 Gemma 4 主模型的质量,只是等待时间变短了。
这个地方很重要。
因为很多加速方案都会让人担心:是不是快了,但答案变差了?
MTP 的卖点就是,速度提升不是靠牺牲主模型质量换来的,而是把原本闲置的计算利用起来。
为什么这对开发者有意义?
Google 在文章里讲了几个场景,我觉得都很实际。
第一是聊天和语音类应用。
这类产品对延迟特别敏感。你和模型说一句话,如果它半天才开始回,整个体验就断了。尤其是语音交互,延迟会被放大很多。
第二是 coding assistant。
写代码时,模型不是只回答一次。它要读文件、规划、改代码、解释错误、再跑下一步。每一步快一点,整个开发节奏就会顺很多。
第三是 agent workflow。
agent 做多步任务时,最怕每一步都慢。单次延迟看起来没什么,但十几步叠在一起,用户就很容易失去耐心。
第四是本地和端侧应用。
比如手机上跑 E2B、E4B 这类边缘模型,生成更快不仅体验更好,还可能省电。因为模型不用长时间占着设备跑。
Google 还做了一些底层优化
这次 MTP 不是简单外挂一个小模型。
Google 在文档里讲到,Gemma 4 的 draft model 会共享主模型的 input embedding table,还会利用主模型最后一层的 activations。
换句话说,草稿模型不是完全独立重新算一遍。
它会站在主模型已经算出来的上下文上继续工作,避免重复计算。
另外,Google 还提到 KV cache 共享。
大家如果跑过推理服务,应该知道 KV cache 很关键。它可以避免模型每次生成新 token 时都从头处理全部上下文。MTP drafter 能和目标模型共享这部分信息,本质上就是让草稿阶段更省。
对于 E2B 和 E4B 这类边缘模型,Google 还做了一个 efficient embedder。简单说,就是不要每次都在完整词表上算最终结果,而是先把相似 token 分组,找到最可能的簇,再缩小计算范围。
这些东西听起来都很底层,但落到产品上就是两个字:更快。
有一个细节:MoE 模型并不是所有情况下都一样快
Google 也提到一个挺真实的工程问题。
Gemma 4 26B MoE 在 Apple Silicon 上,如果 batch size 是 1,会遇到一些专家路由上的挑战。
因为 MoE 模型每个 token 可能会激活不同专家。验证多个草稿 token 时,可能需要加载更多专家权重,这会抵消一部分加速收益。
但如果 batch size 提到 4 到 8,本地最高可以看到大约 2.2 倍加速。Nvidia A100 上也有类似现象。
这个信息我觉得很重要。
它说明 MTP 不是一个“所有机器、所有场景都无脑 3 倍”的开关。
真正部署的时候,硬件、模型结构、batch size、推理框架都会影响结果。
所以如果你要拿它进生产,不要只看宣传数字,还是要在自己的负载上跑 benchmark。
怎么开始用?
Google 说,Gemma 4 的 MTP drafters 已经开放,许可证和 Gemma 4 一样,是 Apache 2.0。
模型权重可以从 Hugging Face 和 Kaggle 下载。
推理框架方面,Google 提到可以用:
- Hugging Face Transformers
- MLX
- vLLM
- SGLang
- Ollama
- LiteRT-LM
如果是移动端,也可以直接在 Google AI Edge Gallery 上试 Android 和 iOS 版本。
官方也给了 MTP 文档,可以从这里看具体用法:
Speed-up Gemma 4 with Multi-Token Prediction
如果你只是想感受一下,我建议先从本地开发环境试。
比如你有 Mac,先看 MLX 方向;你有 Nvidia GPU,可以试 vLLM 或者 SGLang;如果只是想快速上手,Ollama 可能是最省事的入口。
我的看法:下一阶段开源模型会拼“可用性”
我觉得这篇文章真正值得看的地方,不只是 MTP 这个技术点。
它背后反映的是一个趋势:开源模型竞争正在从“参数和榜单”走向“真实可用性”。
以前大家看模型,喜欢看分数。
谁数学强,谁代码强,谁上下文长,谁参数更多。
这些当然重要。
但当开发者真的把模型放进产品、工具、agent 工作流里,另一些指标会变得更重要:
- 首 token 延迟低不低?
- tokens per second 够不够?
- 本地能不能跑顺?
- 手机上能不能跑?
- 推理成本能不能压下来?
- 加速后质量会不会飘?
MTP 这种技术,就是在回答这些问题。
它不是让模型变得更“聪明”,而是让模型更像一个可部署、可交互、可嵌入到产品里的工程组件。
这个方向我很看好。
因为对普通开发者来说,最好的模型不一定是最大、最贵、跑分最高的那个,而是“我现在手头这台机器能跑起来,而且用户等得起”的那个。
Gemma 4 如果能在这个方向持续推进,本地 AI、端侧 AI、离线 coding assistant 这些场景都会更有想象空间。
小结
简单总结一下。
Google 这次给 Gemma 4 发布了 MTP drafters,本质上是通过 speculative decoding,让轻量草稿模型提前预测多个 token,再由主模型并行验证。
这样做的结果是:推理速度最高可提升 3 倍,同时因为最终验证仍由 Gemma 4 主模型完成,所以质量和推理逻辑不需要牺牲。
对开发者来说,这件事的意义很直接:
本地模型更快,agent 工作流更顺,移动端体验更好,产品里的 AI 响应更接近实时。
当然,具体加速效果还是要看硬件、batch size、模型结构和推理框架。
但方向很清楚:大模型接下来不只是比谁更强,也要比谁更快、更省、更容易落到真实产品里。