
大家最近如果一直在看 AI Agent 这一块,应该会有一个很明显的感觉:
现在大家已经不满足于「让模型回答问题」了,开始往更工程化的方向走。就是说,一个 Agent 不只是要会调用工具、会跑任务,还要能记住自己做过什么,知道什么叫「做得好」,甚至在任务太大的时候,能把活拆给别的 Agent 一起做。
Anthropic 在 2026 年 5 月 6 日发了一篇新文章,讲 Claude Managed Agents 的几项更新。里面有三个词很关键:
- dreaming
- outcomes
- multiagent orchestration
直接翻译的话,dreaming 叫「做梦」,outcomes 叫「结果」,multiagent orchestration 叫「多 Agent 编排」。但我们先不要被这些词绕住。它真正想解决的问题其实很朴素:
一个 Agent 怎么越用越聪明?
它怎么知道自己做得好不好?
一个 Agent 干不完的活,怎么交给一组 Agent 去并行处理?
好,我们一个一个来看。
第一个能力:dreaming,让 Agent 在任务之外做复盘
Anthropic 这次把 dreaming 放进了 Claude Managed Agents,目前是 research preview。
这个 dreaming 不是让模型真的睡觉,当然了也不是玄学。它更像我们平时项目结束之后做复盘。
比如说,一个 Agent 这段时间处理了很多 session,也写了一些 memory。那 dreaming 就会定期去看这些历史记录和记忆内容,从里面找规律:
- 哪些错误反复出现
- 哪些流程最后证明比较靠谱
- 团队里不同人有哪些共同偏好
- 哪些记忆已经过时或者噪声太大
然后它会把这些东西整理进 memory 里,让后面的 Agent 工作时能用上。
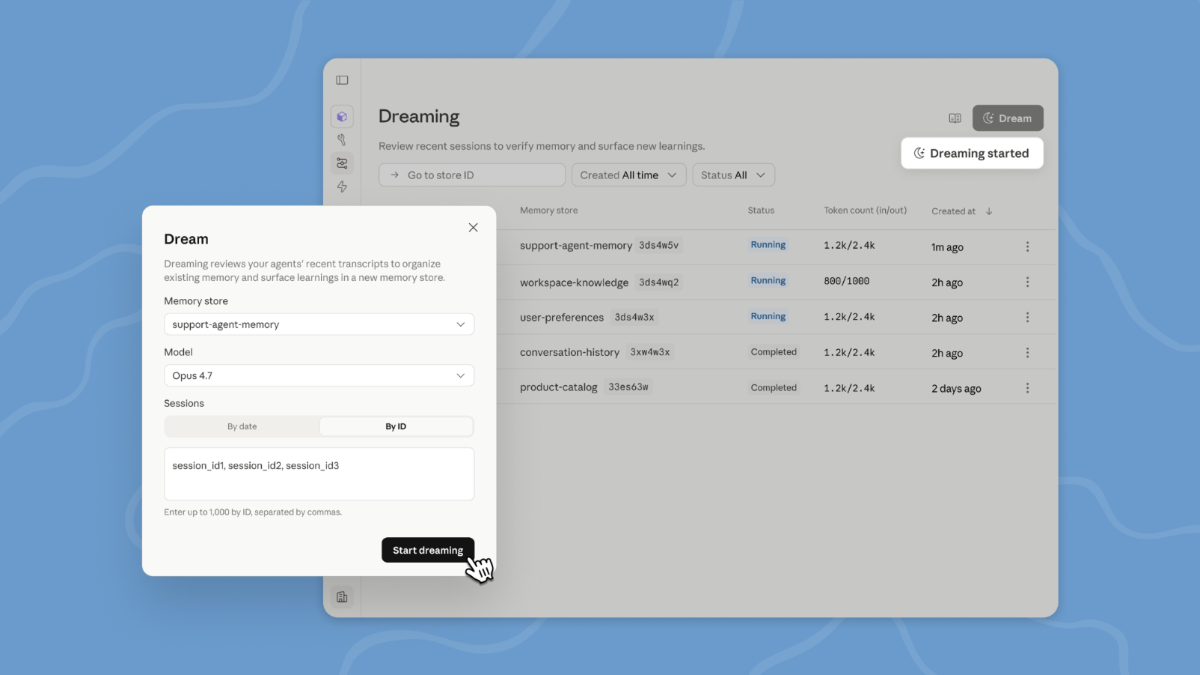
这个地方很有意思。以前我们讲 memory,更多是在说「记住事实」。比如这个用户喜欢什么风格,这个项目里命名规则是什么,这个工具有什么限制。
但 dreaming 更像是「整理经验」。就是说,Agent 不只是把东西塞进记忆里,还会在两次任务之间,把这些记忆重新打磨一下。哪些保留,哪些合并,哪些应该升级成更通用的经验。
实际开发里大家应该很熟悉这种感觉。一个新人刚进项目,会记很多碎片:这个接口怎么调,那个脚本怎么跑,哪个环境变量容易漏。做久了之后,他不会只是记碎片,而是会总结出模式:这个团队的 PR 喜欢怎么写,部署出问题一般从哪里查,某类文件生成时有哪些坑。
dreaming 想做的就是这件事。
当然了,Anthropic 也没有说它一定自动改记忆。开发者可以选择让 dreaming 自动更新 memory,也可以先审一遍,再决定哪些变更真正落地。这个控制权还是给到人的。
第二个能力:outcomes,让 Agent 知道什么叫「做得好」
很多时候 Agent 做不好,不一定是模型能力不够,而是我们没有把「好」定义清楚。
比如你让它做一个 PPT,它可能能做出来。但什么叫好 PPT?
是结构清楚?
是符合品牌规范?
是每页都有结论?
是数据图不能乱编?
是整体文风要像某个团队?
这些东西如果只靠一句 prompt,往往不够稳定。
所以 Anthropic 这次推出了 outcomes。它的思路是:你先写一个 rubric,也就是验收标准,告诉 Agent 成功长什么样。Agent 做完之后,会有一个单独的 grader 去检查结果。
这个 grader 有自己的 context window,不会被 Agent 自己的推理过程带偏。它只看最终结果和验收标准,然后指出哪里没达标。Agent 再根据反馈重做一遍。
大家可以把它想象成一个内置的 code review 或稿件编辑。不是让 Agent 自己说「我觉得挺好」,而是另外安排一个角色,用同一套标准去验收。
这个能力特别适合两类任务。
一类是细节要求很多的任务。比如文档生成、文件格式、长列表覆盖、合规检查。只要漏一个点,结果就不算好。
另一类是比较主观但仍然可以写成标准的任务。比如文案是不是符合品牌语气,设计是不是符合视觉规范,文章是不是像某个人的表达风格。
Anthropic 说,在他们内部测试里,outcomes 相比普通 prompting loop,任务成功率最高提升了 10 个百分点。文件生成质量也有提升,docx 任务成功率提升 8.4%,pptx 提升 10.1%。
这个数字当然要看具体 benchmark,但方向是清楚的:未来 Agent 系统里,生成只是第一步,验收和返工会越来越重要。
另外,现在也可以定义一个 outcome,让 Agent 自己跑,完成之后通过 webhook 通知你。就是说,不需要人一直盯着它一轮一轮改。
第三个能力:multiagent orchestration,让一个主 Agent 带一队专员
很多复杂任务,单个 Agent 不是不能做,而是做起来容易乱。
比如线上出问题了,你要查部署历史、错误日志、监控指标、support ticket,还要把这些信息串起来找根因。一个 Agent 慢慢翻也可以,但它的 context、时间和注意力都会被拉得很长。
multiagent orchestration 解决的是这个问题。
它允许一个 lead agent 把任务拆开,然后分给不同的 specialist agent。每个 specialist agent 可以有自己的模型、prompt 和工具。
比如说:
- 一个 Agent 查 deploy history
- 一个 Agent 看 error logs
- 一个 Agent 跑 metrics 分析
- 一个 Agent 汇总 support tickets
- lead agent 负责把这些结果串起来,做判断
这些 specialist agent 可以并行工作,而且共享文件系统。它们做过什么、为什么这么做,事件都会被保留下来。lead agent 在中途也可以回来问它们进展。
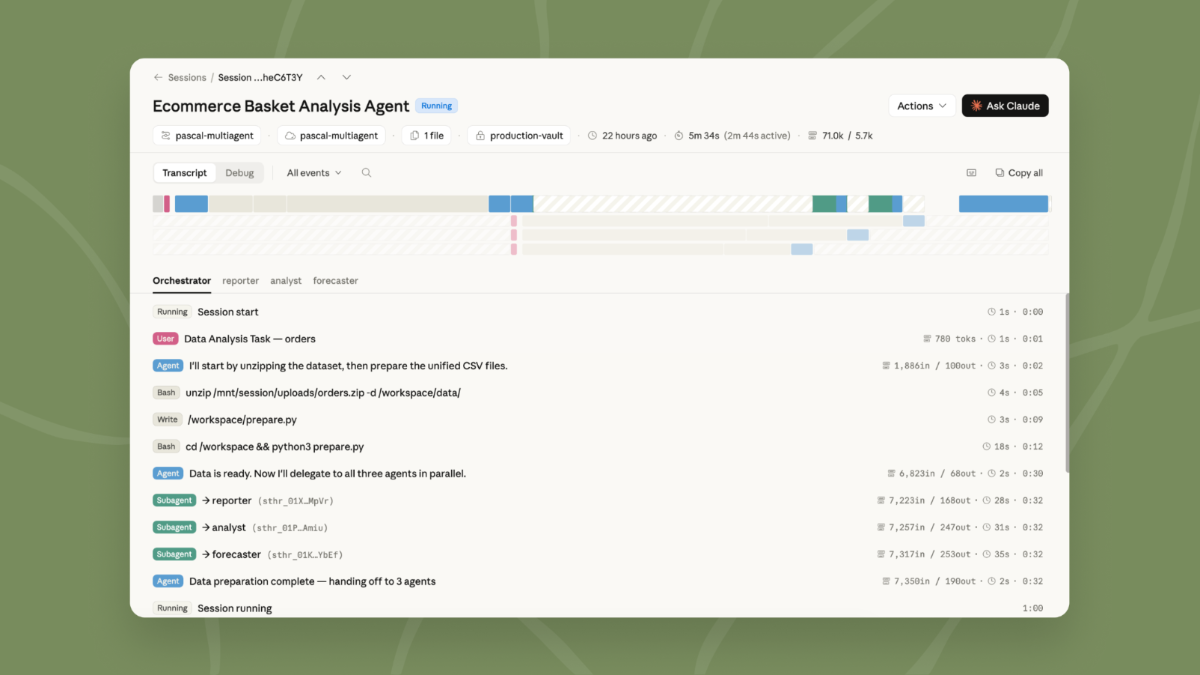
这个地方的关键不只是「并行」。并行大家都懂,开多个任务就好了。关键是可追踪、可协调、可回放。
Anthropic 提到,在 Claude Console 里可以看到每一步:哪个 Agent 做了什么,按什么顺序做的,为什么这样做。对于企业场景来说,这个很重要。因为你不能只看到一个最终答案,你还要知道这个答案是怎么来的。
一些团队已经在这样用了
Anthropic 文章里也放了几个案例,基本都围绕「复杂工作」「质量标准」「跨 session 学习」这几个关键词。
Harvey 用 Managed Agents 来协调复杂法律工作,比如长文起草和文档创建。dreaming 让它们的 Agent 能在不同 session 之间记住经验,包括文件类型绕坑、工具使用模式等。他们测试里完成率提升了大约 6 倍。
Netflix 的平台团队做了一个分析 Agent,用来处理来自不同来源的数百个 build 日志。对于影响成千上万个应用的变更来说,真正重要的不是每个错误都看一遍,而是找出反复出现、值得处理的模式。多 Agent 编排可以让它并行分析不同 batch,最后只把有价值的模式浮出来。
Every 的 Spiral 在自己的写作 Agent 里用了 multiagent orchestration 和 outcomes。它们的 lead agent 跑在 Haiku 上,负责接收请求、必要时问几个补充问题,然后把写作任务交给跑在 Opus 上的 subagents。用户要多个 draft 的时候,subagents 可以并行写。
这里比较有意思的是,Spiral 把写作质量也做成了 outcome。每个 draft 都会按 Every 的编辑原则和用户自己的 voice 来打分,只有过线的稿子才返回。
Wisedocs 则用 Managed Agents 做文档质量检查。它们用 outcomes 按内部规范给每次 review 打分。结果是 review 速度快了 50%,同时还能保持团队标准一致。
这背后的趋势:Agent 正在从「模型能力」走向「系统能力」
我觉得这次更新有一个很重要的信号:
Agent 的竞争,已经不只是模型本身有多聪明了。
当然,底层模型还是很重要。但真正落到企业和开发者手里,你会发现还有很多系统问题要解决:
- 记忆怎么维护,不能越用越脏
- 质量怎么验收,不能全靠人肉检查
- 大任务怎么拆,不能一个 Agent 硬扛
- 过程怎么追踪,出了问题要能回看
- 不同 Agent 之间怎么协作,不要各干各的
Claude Managed Agents 这次的 dreaming、outcomes 和 multiagent orchestration,其实就是往这些方向补能力。
用一个简单的类比来说:
以前的 Agent 像一个很聪明的实习生。你给它任务,它能做,但你得盯着,得反复说标准,也得提醒它之前踩过什么坑。
现在的方向是,把它变成一个会写工作日志、会参加复盘、会按验收标准自检、还能带几个专员一起干活的小团队。
这个变化很大。
因为真正的自动化,不是「一次生成一个答案」。真正的自动化是:任务能持续推进,质量能被检查,经验能沉淀下来,过程还能被人理解。
最后
按照 Anthropic 的说法,dreaming 现在是 research preview;outcomes、multiagent orchestration 和 memory 已经作为 Managed Agents 的 public beta 能力开放。想试 dreaming 的开发者需要申请 access,其他能力可以从文档和 Claude Console 开始看。
好,这篇文章的核心就这些。
如果只记一句话,我觉得可以这么理解:
Claude 这次不是在说「Agent 又会了一个新技巧」,而是在把 Agent 往一个更完整的工作系统上推。它要会记、会复盘、会验收、会协作。
这也是接下来 Agent 真正能不能进生产环境的关键。