别让 Agent 烧穿你的账单:四个省 Token 的实战思路
大家都知道了,AI Agent 上线跑起来是真的烧钱。
你想啊,第一个版本可能系统提示词就 500 个 token,挂两个工具,看着挺轻量的。但一旦这个 Agent 开始"长大",数字就跟着飞涨。
给大家看几个真实的例子:泄露出来的 Claude 系统提示词大概 24,000 个 token,GPT-5 的也有 15,000 左右。有人在 GitHub 上吐槽,说 Claude Code 里一个空文件夹,你就说一句"hi",结果直接干掉了 31,000 个 token。OpenClaw 的用户更夸张,第一轮对话给 Gemini 3.1 Pro 发了超过 150,000 个输入 token,最后就换来 29 个 token 的输出。
再加上各种工具定义和 MCP 服务器,数字就更离谱了。光是工具定义就能吃掉好几万 token。如果你还不管工具的输出和对话里的历史垃圾,那每一轮你都在为这些没用的东西买单。
不优化的话,一天 100 条消息、每条 166K 输入 token,用 Gemini 3.1 Pro 一个月大概要 $996,换成 Claude Opus 4.6 就得 $2,490。
当然了,省钱的招数是有的,只是很多生产环境的团队没用好。所以今天我们一个一个来聊,聊透了。
我会在文章里放一些交互式的图表,方便大家直观感受每个方法能省多少钱。当然了,每一条省钱的路都有代价,这点我会一直说。
四个设计原则
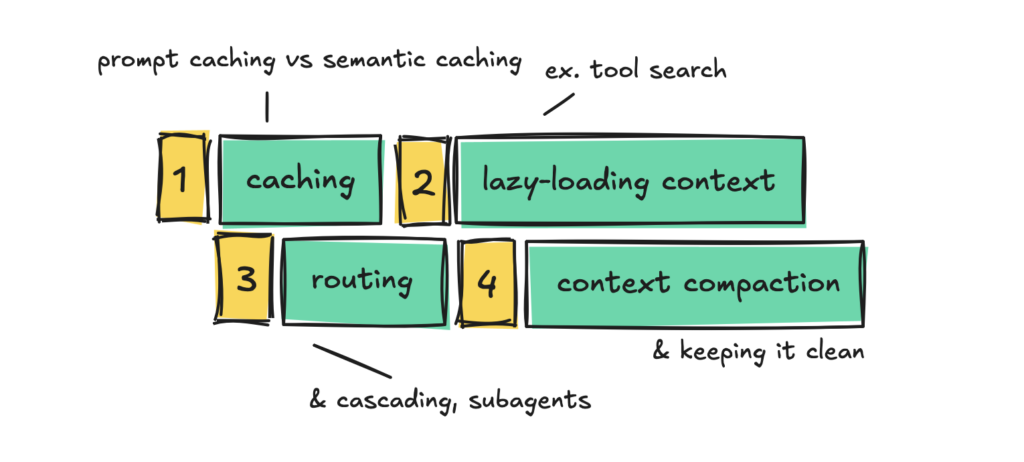
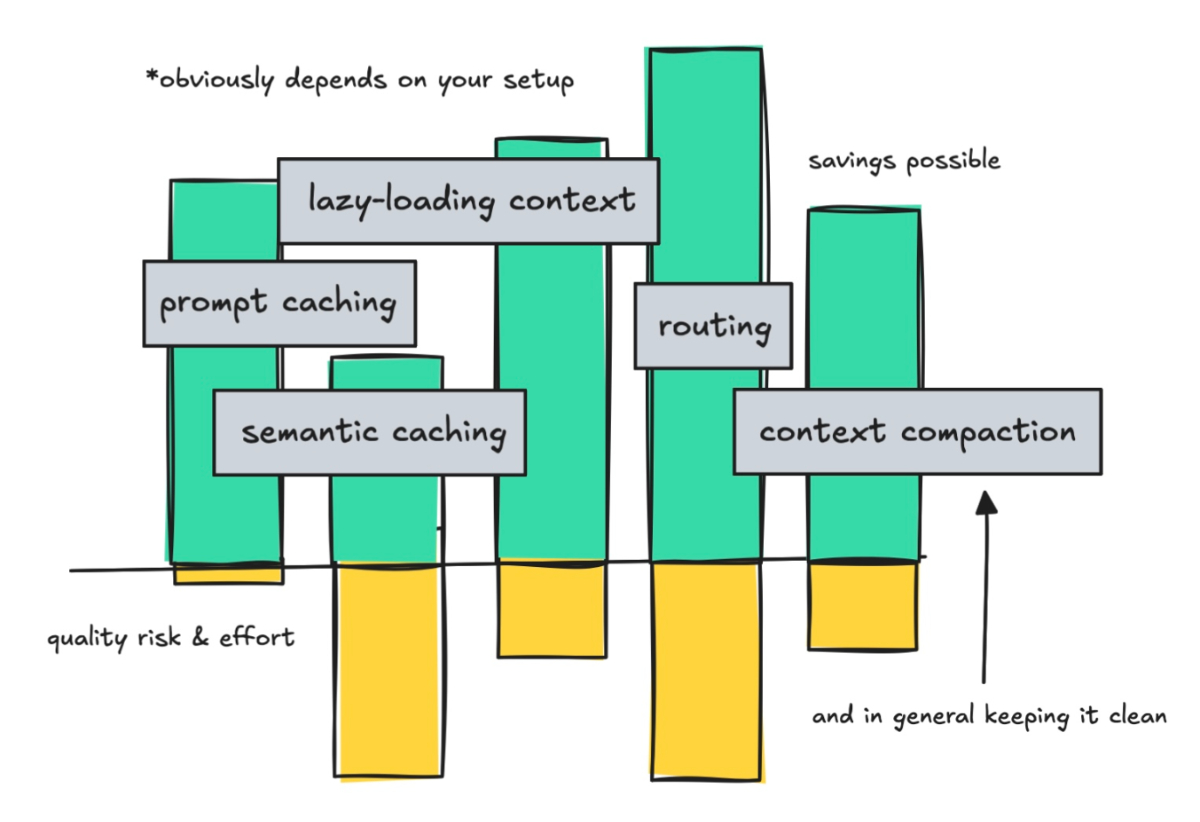
好,我们先整体看一下今天要讲的四个方向:
- 尽可能复用 token — 也就是 prompt caching 和语义缓存
- 别提前加载用不到的 token — 比如工具定义的懒加载
- 简单的活用便宜的模型 — 路由、级联、子 Agent
- 保持上下文干净 — 状态管理和上下文压缩
每个方向我都会配一个交互计算器,大家可以根据自己的 token 用量来算。
一、尽可能复用 token
LLM 的成本不只是"调用了多少次模型",还有很大一部分来自反复处理同一批 token。所以这一块我们先聊聊 K/V 缓存——也就是 prompt caching 底层的机制,然后说语义缓存。这俩是两码事,我们分别来看。
Prompt caching 是长系统提示词的快速优化,语义缓存则需要更多的工程投入,风险也更大。
K/V 缓存和前缀缓存
模型在生成任何内容之前,得先把 prompt 处理一遍。这一步叫 prefill。Prefill 要消耗算力,算力就是延迟,就是钱。所以说,同样的内容我们不应该反复处理。
当你用大语言模型的时候,prompt 先被分词(tokenize),然后这些 token 变成向量(vector),再在每个注意力层里被投影成 K/V 张量。
推理引擎在生成过程中必须缓存这些 K/V 张量,不然数学上跑不动,速度也没法接受。生成完了之后,它就把缓存扔掉了。
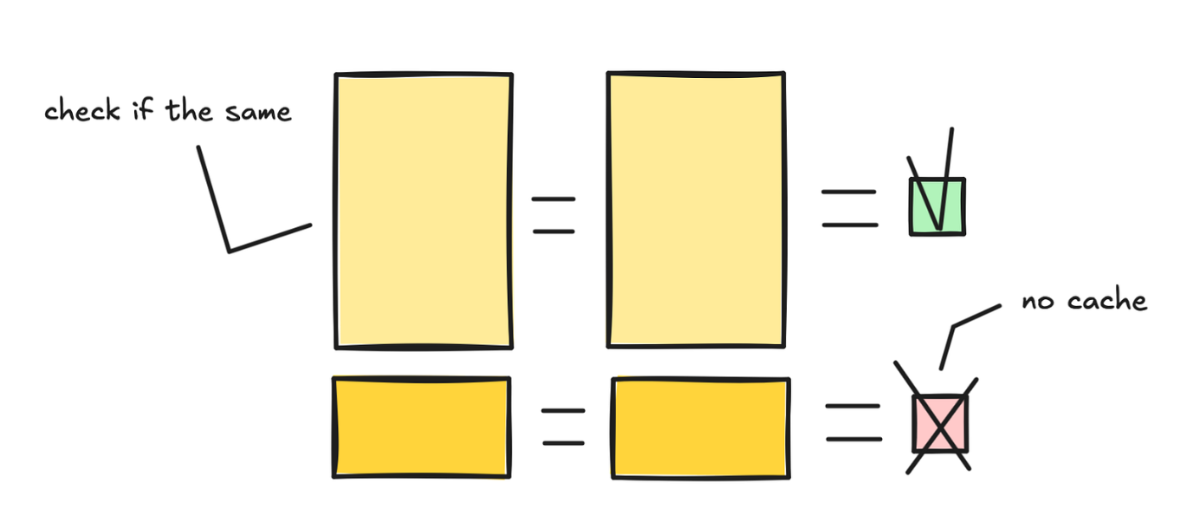
但是我们可以不扔啊。把这个缓存存下来,打个标签,下次好找。
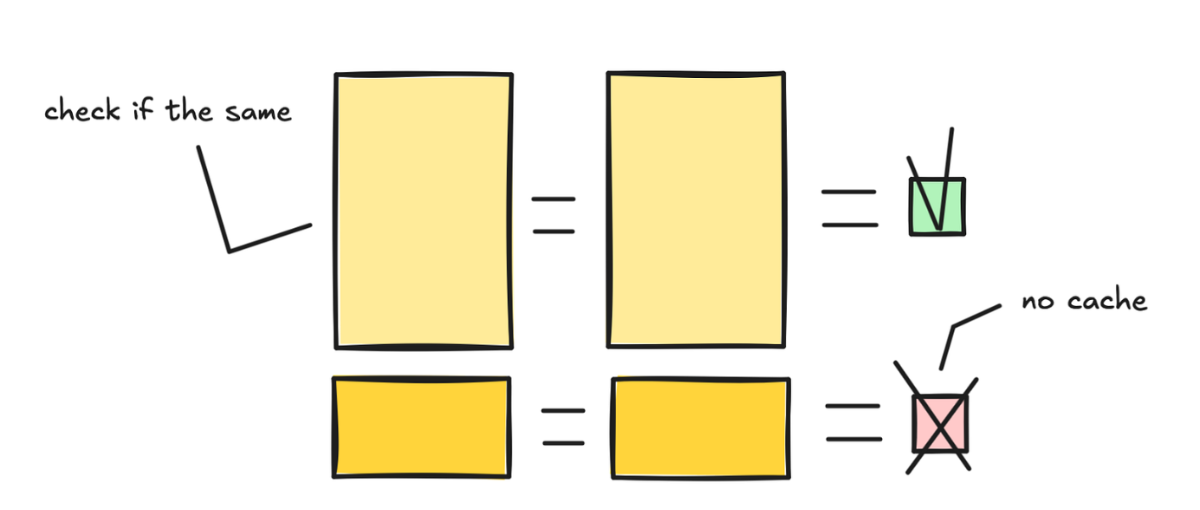
下一次请求进来,我们先检查 prompt 开头是不是有跟已存储的 K/V 张量匹配的部分。如果有,直接加载,跳过重复处理。
给大家算一笔账,感受一下为什么这事儿很重要:假设处理 2,000 个 token 要 1 秒钟,你的系统提示词有 10,000 个 token。那就是每次 LLM 调用省 5 秒,仅仅是因为不用反复跑同一坨 prompt 前缀。当然了,prefill 的吞吐量因环境差异很大,这里只是给个感觉。
有一个很关键的地方要注意:文本必须完全匹配才能命中缓存。哪怕多了一个空格、工具定义换了个顺序、时间戳放错了位置,缓存就废了,得重新算。这是很多人踩的坑。
所以存缓存确实能加速请求,也让请求更便宜。不过存储这些张量也不是免费的,它要占服务端的内存。
好消息是我们不需要自己造轮子,上面说的只是帮大家理解原理。现成的框架有,API 厂商也有自己的 prompt 缓存规则,我们后面都会聊到。
自部署推理的前缀缓存
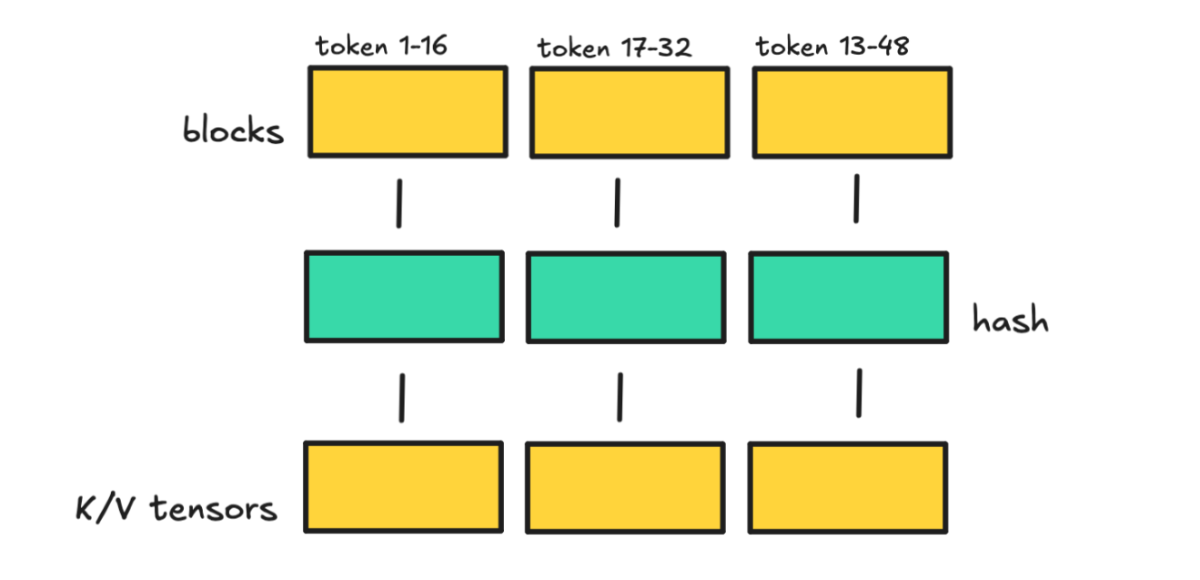
如果你是自己部署开源模型,一般会用一个 LLM serving 框架,比如说 vLLM。vLLM 有一个附加功能我们可以用一下。
它的做法是:把 prompt 切成块(block),根据每个块的 token(加上前面的 token)做哈希,然后把 K/V 张量存在对应的哈希下面。
跟大多数方案一样,需要缓存的静态部分应该放在 prompt 的最前面。
在 vLLM 里开启缓存用 --enable-prefix-caching 这个参数。
还有其他参数可以调,比如 --block-size,还可以用类似 --kv-cache-memory-bytes 的参数来显式设置每个 GPU 的 KV 缓存大小。
Block size 就是一个块里有多少 token。如果 block size 是 16,那就是每 16 个 token 切一刀。
给它的内存越多,缓存块就能留得越久。但如果同时有大量不同的长请求在跑,内存很快就满了,老的缓存块就会被更快地挤掉。
市面上还有其他方案,比如 SGLang 和 RadixAttention 也做前缀缓存,LMCache 也能接到 serving 引擎上。原理都一样。
不过大多数人还是用 API 厂商,它们有自己的 prompt 缓存策略,我们来过一遍。
通过 API 厂商使用 Prompt 缓存
用 API 厂商的话,你需要把 prompt 结构组织好,才能命中缓存。这里面有一些讲究。
我先拿 OpenAI 来举例。
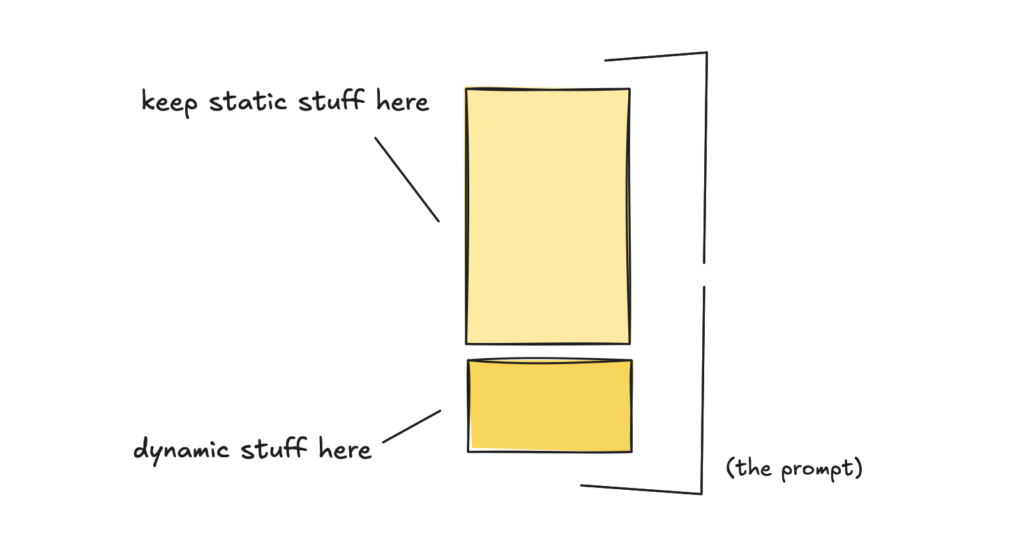
OpenAI 说得很明确:要缓存 prompt 的某一部分,需要完全的前缀匹配。也就是说,prompt 开头必须是完全一样的静态内容。
这就意味着你得把稳定的指令、示例和工具定义放前面,会变化的内容放后面。
你还可以发一个 prompt-cache-key,帮助把类似的请求路由到同一个缓存上,提高命中率。
还有一些细节:缓存是自动开启的,但只对 1,024 token 以上的 prompt 生效。而且它用前 256 个 token 来路由请求到对应的缓存。所以你的静态部分至少得超过 256 token。
Anthropic 那边呢,你需要用 cache-control 参数来手动开启缓存。
另外提一下,缓存淘汰(TTL)一般在 5 到 10 分钟不活动后触发,但可以延长。Anthropic 也是类似的规则,不过你可以推到 1 小时(但要花 2 倍的钱)。
前面我讲了省时间,如果是自部署的话也能省钱。用 API 厂商的话,省的钱体现在"缓存的输入 token 更便宜"。
OpenAI 的缓存输入 token 最多能打 1 折。Anthropic 也是同样的折扣,但你还得多交一笔缓存存储费。所以如果你用得不对,Anthropic 反而更贵。
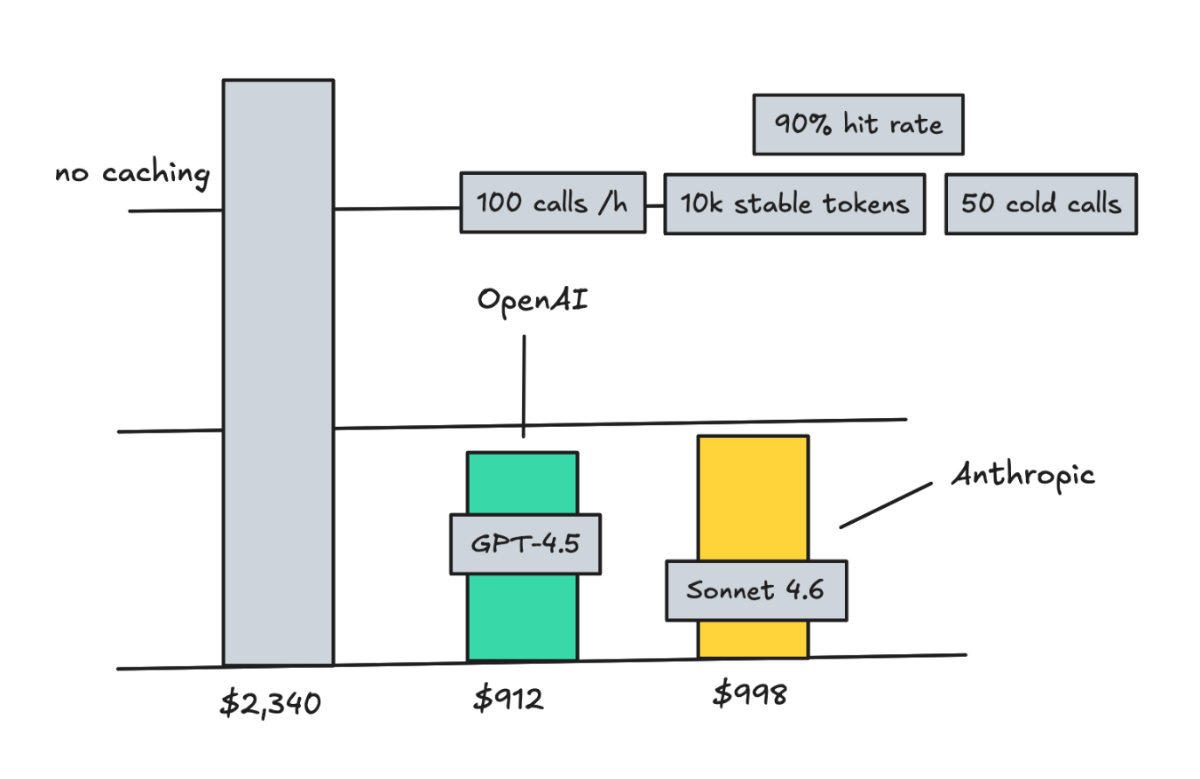
总的来说,如果你的 prompt 有 90% 是静态的,缓存命中的情况下能省 80%。
语义缓存
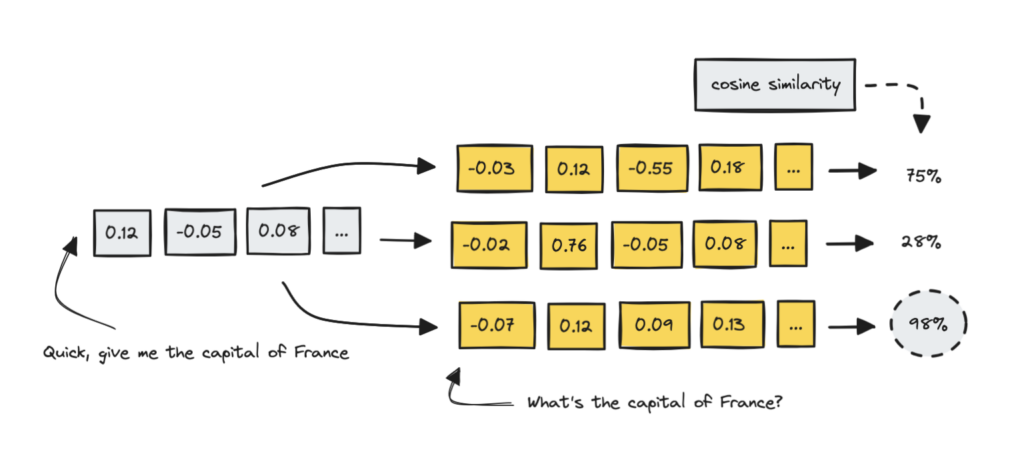
语义缓存是按意思来匹配的。就是说,如果两个请求的意思差不多,就直接返回缓存的结果。听起来简单,但坑不少。
要做语义匹配,我们用 embedding(嵌入向量)。如果你不熟悉这个词,可以去搜一下。我之前也写过一篇关于 embedding 的文章,感兴趣可以翻翻。
简单来说,embedding 就是一个向量,我们可以用余弦相似度来比较它们。相似度高,意思就应该差不多——当然也取决于模型。
语义缓存想做的事情就是:把类似的请求指向已经存在的答案。比如问"法国的首都是哪?"和"告诉我法国的首都",应该走到同一个答案。
没必要让 LLM 一遍一遍回答同样的东西。
如果你的场景是很多人问差不多的问题,而且数据不会很快过时,这个方案就行得通。
那为什么不在所有场景都这么做呢?坑太多了。
随便想几个:相似度的阈值怎么设?答案的有效期多长?多轮对话怎么办?到底存什么?要不要加路由?怎么区分不同用户?如果缓存了错误的答案怎么办?
你还得考虑 TTL(Time to Live),也就是信息什么时候会过时,哪些问题需要更短的 TTL。
所以虽然原理很简单,你还是要加元数据过滤和标签,比如用户、工作区、语料库版本、角色、会话/用户作用域、智能 TTL,再加一些"这个返回够不够好"的规则。
这就变成一个不小的工程了。
如果你真想做,我建议先用语义索引去找之前的类似问题。不同的问题可以指向同一个缓存的答案,这样存储不会爆炸。TTL 要按使用频率来定——经常被复用的就留久一点,不常用的就删掉。
还有,我建议你先看日志里有没有明显的重复模式,再决定要不要上语义缓存。也许你的场景根本不适合。
至于怎么做,很多数据库都能搞定。也有现成的库,比如 semanticcache、prompt-cache、GPTCache、vCache、Upstash semantic-cache、Redis + LangCache。
这里确实能省钱。Redis 声称能减少 68.8% 的 API 调用,延迟降低 40-50%。不过要注意这是营销数据,他们用的是典型的 Q&A 场景。
所以说完全取决于你的场景。如果你是 Q&A Agent,大量重复调用,那能省不少。如果是编程助手,每次调用都不一样,就省不了多少。
Prompt caching 适合大 prompt 里的不变部分 + 一直在变的问题。语义缓存适合同一个问题被用不同方式反复问。
好,在离开这一节之前,我还想提醒一下:普通的缓存也能省不少钱。那些昂贵但确定性的东西——SQL 查询结果、工具输出、检索结果——一定要缓存,别跑了一遍又一遍。
我自己有个工具就是这么干的。它采集关键词数据做摘要,然后缓存起来,等数据过期了再重新跑。
好,语义缓存这个想法挺有意思的,在特定场景下确实能省 token,但要做得好得花功夫。
二、别提前加载用不到的 token
这一块说的是:当你的系统提示词开始膨胀——比如工具定义越来越多、记忆系统越来越大——该怎么办。
小 Agent 倒不是什么问题,但如果你在做那种会持续"长大"的 Agent 架构,就需要想办法瘦身,按需获取信息。
保持上下文精简,按需拉取细节
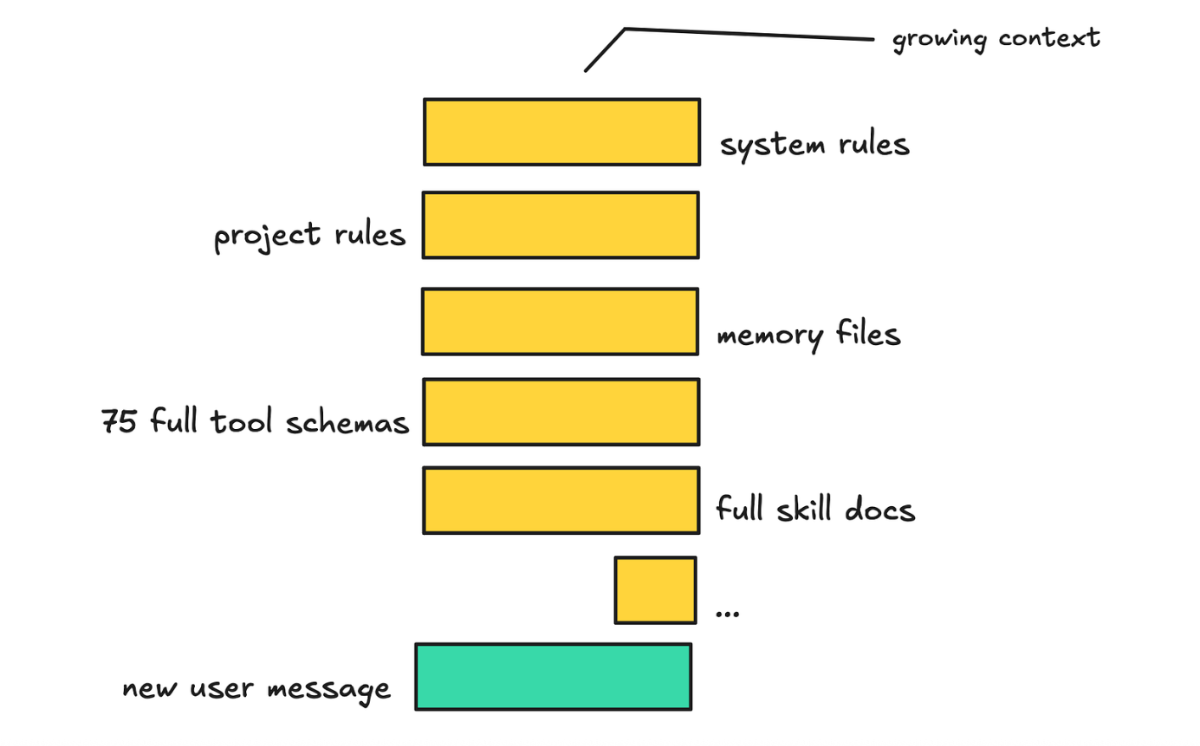
当你的 Agent 提示词膨胀到一定程度后,最好把"始终加载的那一层"做得尽量小、尽量稳定,把不断增长的细节部分单独放。
这很关键,因为一旦这些层开始膨胀——比如加载了几百个工具,或者发了一堆不断变化的 MCP 服务器描述——整个 prompt 就变得很吵。
问题不只是钱,还有性能。而且如果某一层一直在变,prompt caching 就很难命中。
所以思路是:最上面那层保持精简和稳定。这一层帮模型理解"我在哪"和"下一步去哪",但不需要一开始就把所有东西都塞进去。
如果你看过 Claude Code 的源码,你会发现它的记忆系统就是用的这个思路。
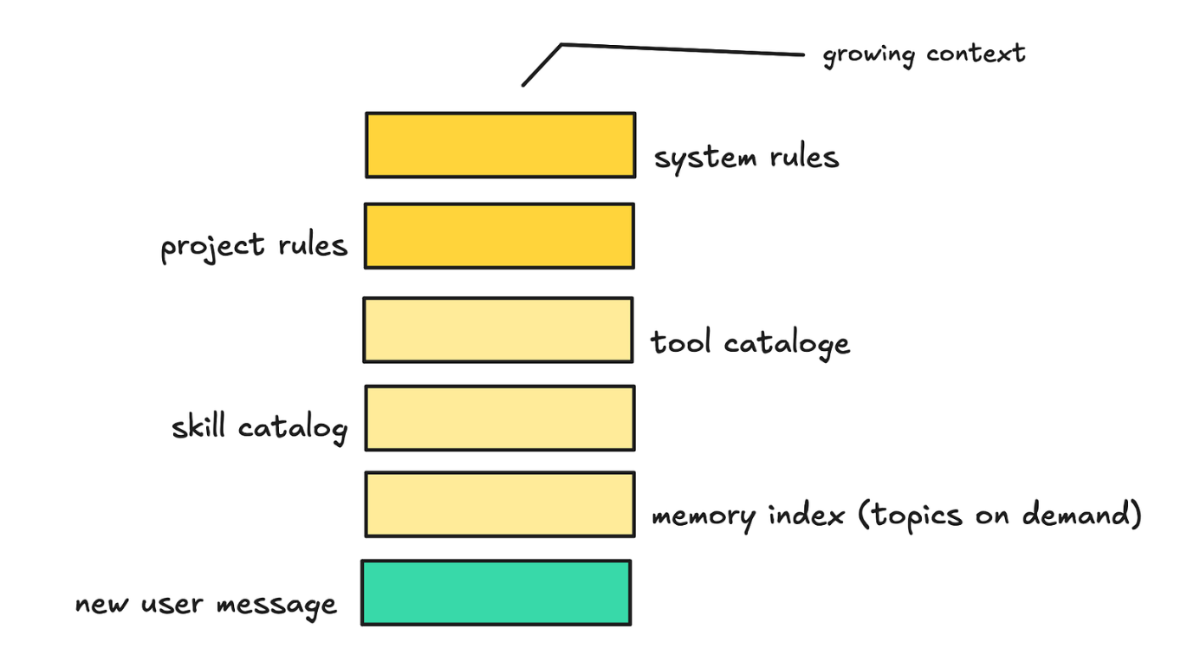
它有一个始终加载的索引文件,控制在 200 行以内,详细的专题文件放在别的地方。当然了,Agent 实际的行为和系统设计想要的行为之间,有时候还是有差距的——这个以后再聊。
同样的思路在其他地方也能看到:Claude 的高级工具设置、Claude Skills 的分层架构,还有尝试懒加载 MCP 工具,而不是一开始就把所有服务器定义都塞进 prompt。
现在谁在做,效果怎么样
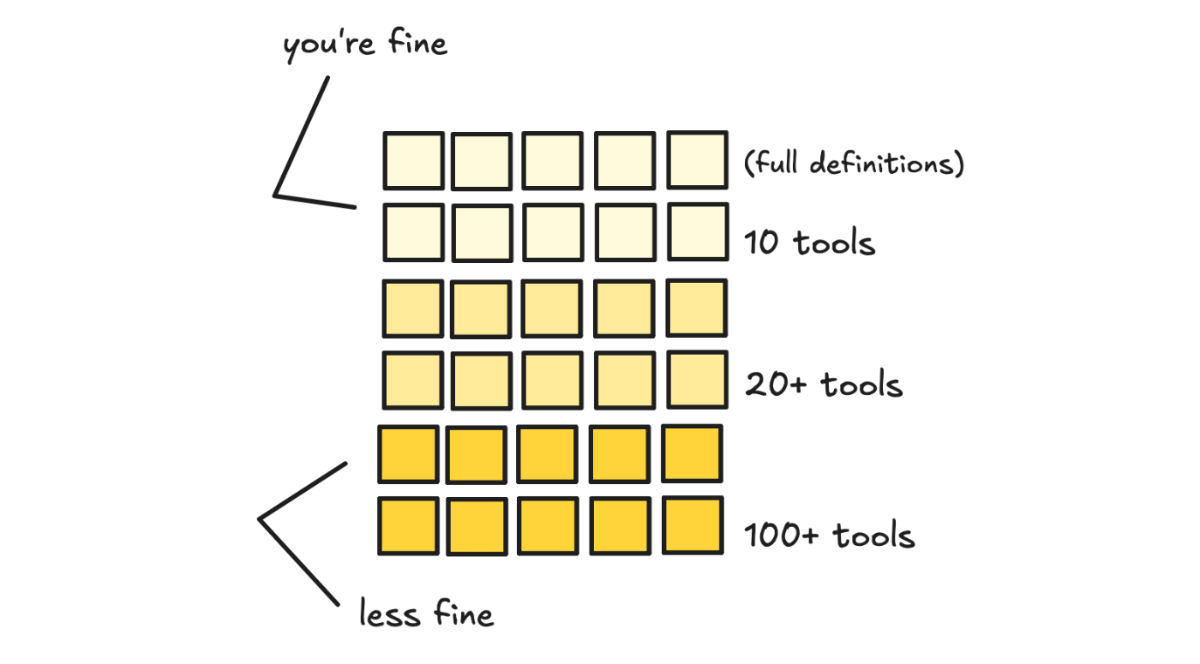
这个思路是对的。上下文越长,LLM 越难选对操作。但这个领域还比较早期,我们来通过一个具体的工具看看怎么落地。
几个月前,Anthropic 发布了一个叫 Advanced Tool Search 的功能。解决的就是:怎么在上下文保持精简的同时,还能让模型访问几百个工具。
Anthropic 说他们见过优化前 55K 到 134K token 的工具定义,而且当上下文膨胀到这个程度时,选错工具是一个非常常见的失败模式。
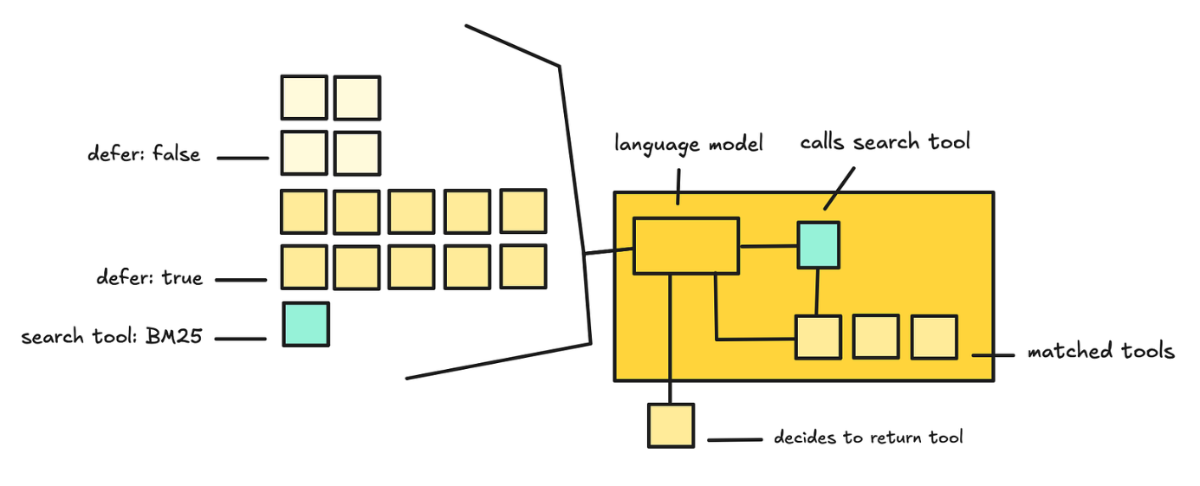
所以解决方案是给一个搜索工具,让 LLM 用它来找工具,而不是把所有工具定义都提前塞进去。
大家看上面的代码,我们定义了一个叫 tool_search 的工具。你可以用现成的 BM25 或 Regex 搜索器,也可以自己做一个。然后我们把一个工具标记为 defer_loading(延迟加载)。
一般来说,工具超过 10 个的时候才值得这么做。
搜索是 Anthropic 帮你做的,所以你看不到它怎么把工具 schema 加到系统提示词里,也看不到底层搜索过程。
他们说的是:一旦匹配到了工具,就把它的定义以内联 tool_reference 块的方式追加到对话里。
这个想法很巧妙:初始上下文更小了,但多了一个搜索步骤。不过也有人测了一下,效果不是很惊艳——但那是 4,000 个工具的极端场景,还有更多测试空间。
而且这还要求我们把工具描述写得够好,让它能被搜到。但问题是,当你看不到中间步骤的时候,调试就变难了。
这个思路在其他地方也有体现,但大家一般就叫它"好的 AI 工程"。不要把一大堆乱七八糟的上下文暴露给 Agent。给它一个缩小范围的方式,等需要的时候再加载。
这一块确实能省不少钱,不过具体能省多少取决于你一开始发了多少 token。
Prompt caching 和懒加载工具都能省钱,但两个一起用的话,边际收益没你想的那么大。Tool search 不只是为了省钱,它还能让上下文更干净,性能更好。
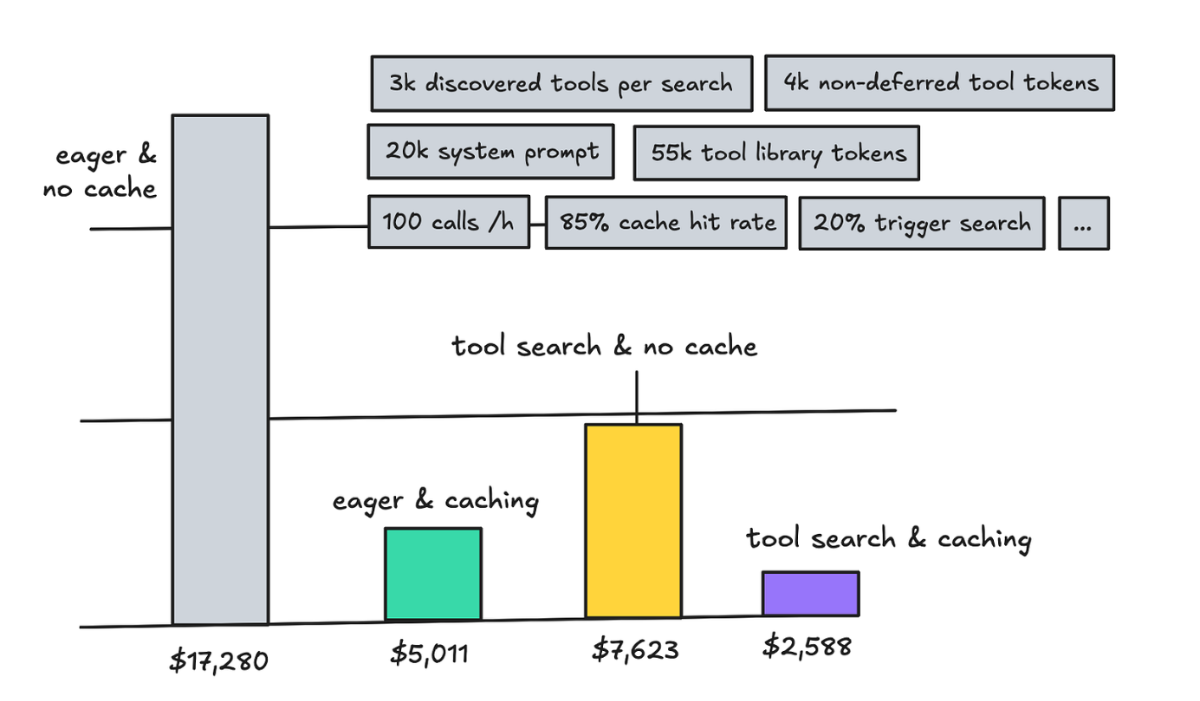
但如果你纯粹是为了省钱,至少选一个用上就好。
三、简单的活用便宜的模型
这一节是关于根据任务难度把 prompt 路由到不同的模型,以及用更便宜的模型做子 Agent。能降 token 成本,但也有质量风险。
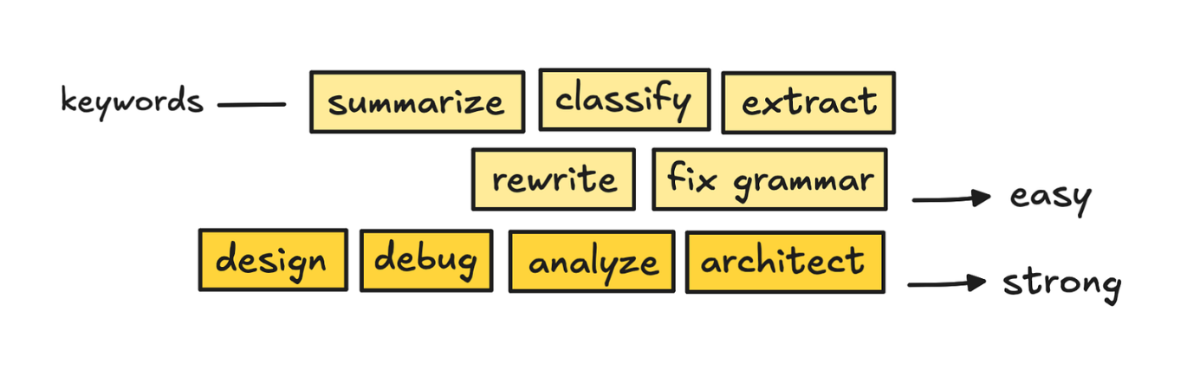
这个领域很有意思,因为很多人说超过 60% 的请求其实是简单任务,根本不需要最强的模型,更不需要 thinking 模型。
ChatGPT 用的是对话类型、复杂度、工具需求和明确意图(比如"仔细想想")这些信号来做路由。Claude 用的是基于描述的委派和内置子 Agent,比如 Explore。
思路很简单,但要在不牺牲太多质量的前提下做好,才是真正的难点。
我们来看看预测路由和输出检查两种方式——级联和子 Agent。
按任务难度路由到不同模型
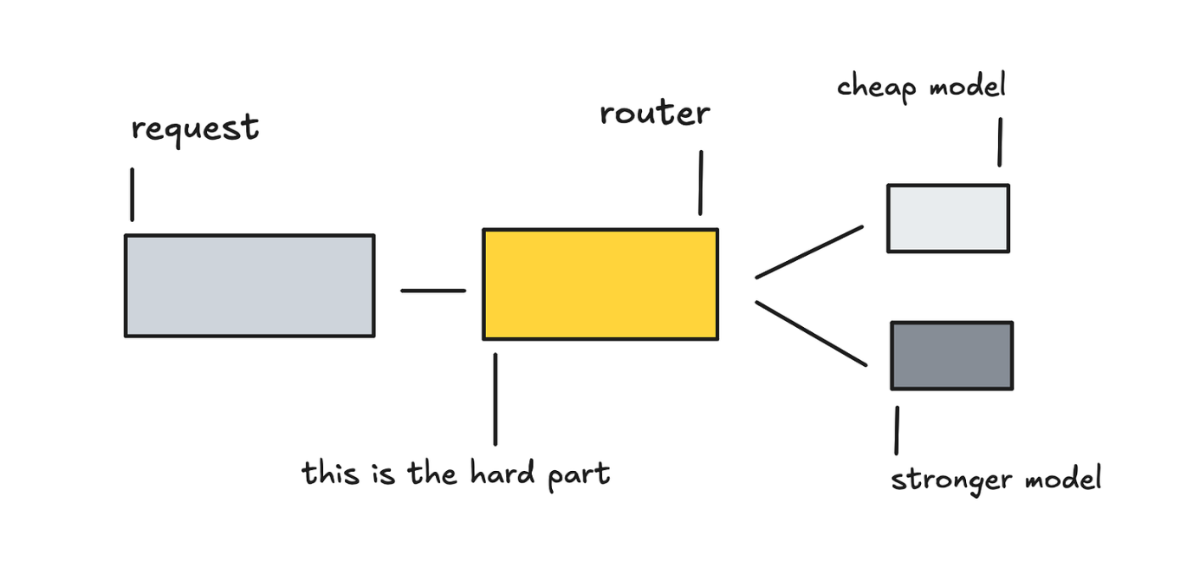
请求级路由的意思是:在看到任何输出之前,先估计任务的难度和意图。收益很高,但如果选错了,整个会话都会受影响,所以有质量上的代价。
要实现这个,你需要一个路由模型来决定把请求发到哪。
我们不清楚 OpenAI 具体用什么信号来路由到不同模型,但说真的,我经常觉得自己被分配到了一个不太行的模型上,有时候挺让人抓狂的。
不过开源社区还是有一些方案的。我们可以看看 LMSYS 的 RouteLLM,就是做 Chatbot Arena 那个 Berkeley 团队的项目。它从 Chatbot Arena 的真实偏好数据中学习。
RouteLLM 用的是标准的 embedding 加一个很小的路由头,所以部署成本应该不高。
我自己没测过 RouteLLM,但他们报告说在保持大部分 GPT-4 性能的同时,大幅降低了成本。
不过我也看了 LLMRouterBench 这篇论文,它基本上说很多"学出来的"路由器,跟简单的基线方法比——比如关键词/启发式路由、embedding 最近邻、kNN 路由——好不了多少。
也就是说,那些花哨的路由器可能并不比你随便写几条规则强多少。
至于用更大的 LLM(比如 Haiku)当路由器,那省下来的钱又被路由器自己吃掉了,感觉没意义。一个小的微调分类器有部署成本,手写的规则路由又太脆。
大家没有因此放弃路由,但都还在摸索,所以如果你的路由质量跟不上,那省钱效果就很难说是稳的。
市面上也有开箱即用的方案,比如 OpenRouter Auto 和 Switchpoint。但它们的路由内部机制和准确率数据都没有公开。
先用便宜模型试,不行再升级
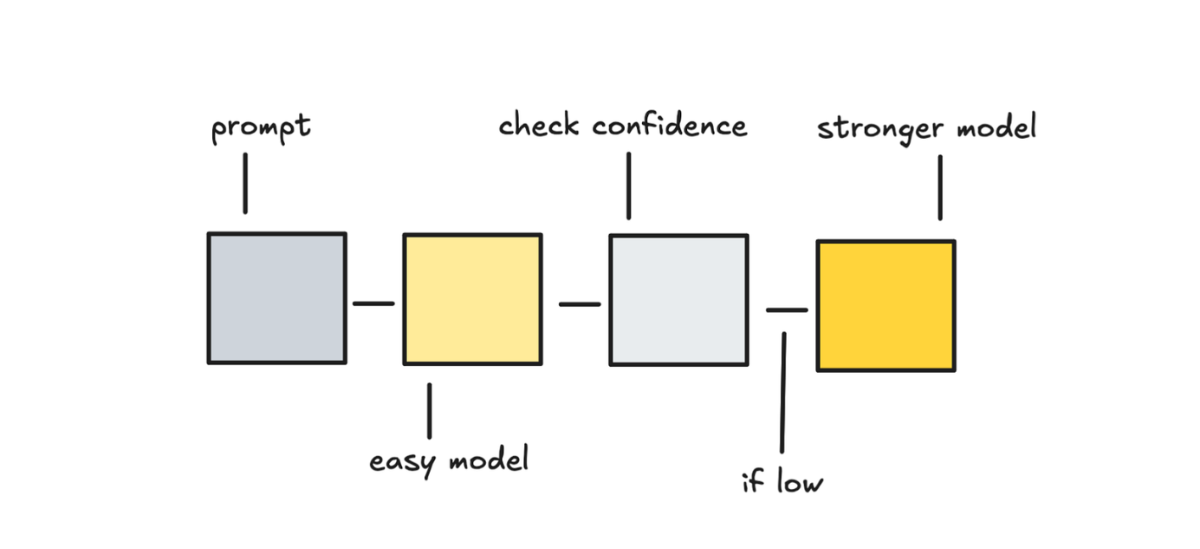
除了从 prompt 猜测请求是"简单"还是"困难",我们还可以让便宜模型先试,然后看它的回答行不行,不行再升级到贵的模型。
Google 的 "Speculative Cascades" 讲的就是这个权衡:先用小模型省成本、提速度,只有在需要的时候才升级到大模型。
做法是:先让便宜模型生成回答,然后用一个轻量的检查器来评估——看 logprobs/token 概率、熵或置信度间距之类的指标,再加上语义对齐程度。
这个思路挺有吸引力的。因为 prompt 的难度经常很难预测,大多数路由器也不完美。而且有了答案之后再判断质量,比在回答之前猜要容易得多。
但这也只有在大部分问题能被简单模型回答的情况下才划算,因为升级的那些问题你要付两次调用费。
不过从实际做的人那里了解到,两次调用之间的验证延迟可以控制在 20ms 以内,这还不错。
我看了 CascadeFlow 这个开源实现,声称能省 69%,同时保持 96% 的 GPT-5 质量水平。但要注意他们测的是有明确标准答案的 prompt,比如数学题和选择题。
一个主要的问题是:小模型经常"自信地犯错"。所以一开始最好用保守一点的阈值,多升级几次。这必然会把成本拉高一些。
把活分给子 Agent
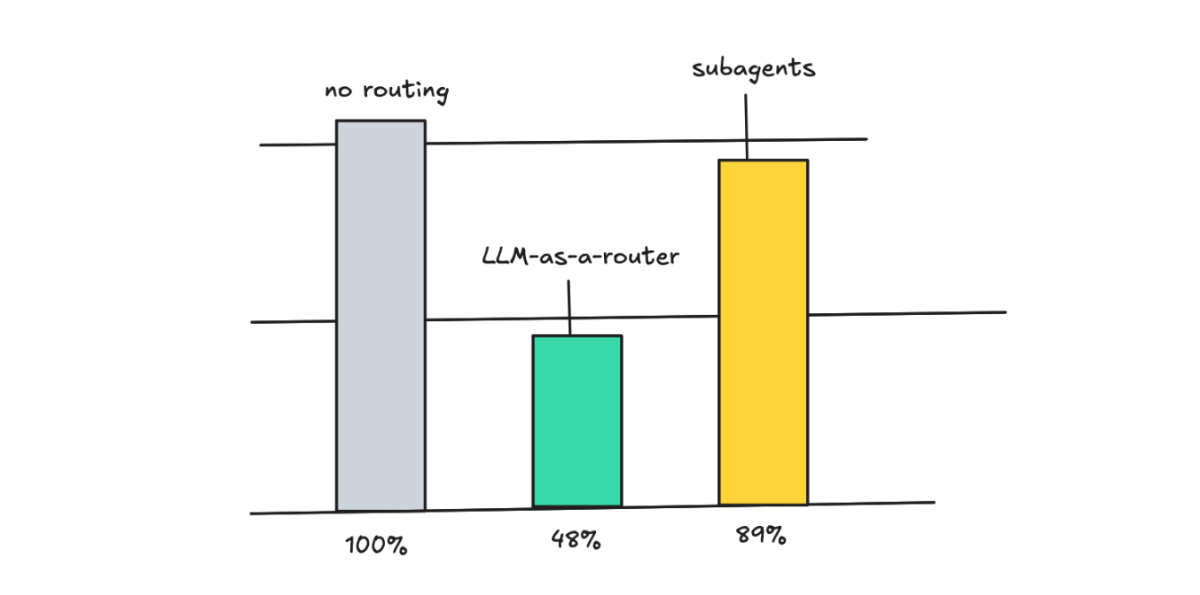
子 Agent 的思路是把工作委派给独立的 Agent。有时候这些子 Agent 用的是更小的模型,所以也可以看作是一种路由方式。省钱效果没那么猛,但值得提一下。
委派给子 Agent 不只是为了省钱,也是为了保持上下文干净,让每个 Agent 能专心做自己该做的事。
Anthropic 的 Claude Code 就内置了子 Agent,很多人应该都见过。Explore 子 Agent 明确就是一个用 Haiku 干活的工作线程,专门做代码库搜索和探索。
主 Claude 会话也会通过描述匹配来做委派,但我们看不到。只是总成本会更便宜。
但因为编排者通常还在循环里——做规划、综合、重试——所以省的没路由那么多。
子 Agent 大概能省 11% 左右,所以如果你纯粹是为了砍成本,这不是首选。
好,下一篇文章我会深入聊子 Agent,但更多是从任务委派和工作隔离的角度。我们先来看最后一节。
四、保持上下文干净
好的上下文工程通常是为了性能,但其实也可以是为了省钱。所以我们来聊聊上下文压缩,说说保持上下文干净怎么帮你省 token。
问题是,Agent 会不断积累垃圾:工具输出、日志、重复的观察、旧计划、过期的尝试、重复的状态。
特别是第一次做 Agent 的人,经常把结果一股脑塞进主 Agent 的工作状态里。
我自己当然也这么干过,尤其是做原型 Agent 的时候,先看看"跑起来怎么样"嘛。
但也看到有人吐槽 OpenClaw 的上下文堆积问题,所以这事儿到处都在发生。Claude Code 也有人吐槽,因为往里塞东西比清理要容易太多了。
我们简单聊聊,不多展开性能那块——虽然那也是你该做这件事的理由。
难点在于搭建一条状态管线
这是一个两层问题。你不只是在"压缩聊天记录",还得在往工作状态里加东西的时候保持干净。这就变成了很繁琐的工程活。
先说保持上下文干净。我们不希望这种结果开始占满上下文:
坏的状态:
Agent 干了活 → 把工具输出全塞进上下文
→ 读文件 → 把文件全塞进上下文
→ 跑测试 → 把日志全塞进上下文
→ 重试 → 全都留着
真正要做的是:把对的状态保留下来,边走边清理垃圾。
原始输出可以放进归档,只把需要的放进活跃上下文。总的来说,敌人大概率是工具输出的膨胀,所以核心工作是让工具默认少输出噪音。
好的活跃上下文:
[系统规则]
[项目规则]
[用户任务]
[当前工作状态]
保留:
+ 认证逻辑在 auth.ts 和 session.ts 里
+ bug 只在刷新路径出现
+ 失败的测试:session_refresh_keeps_user
+ 刷新时可能发生了覆盖
+ 相关文件:auth.ts, session.ts, auth.test.ts
丢弃:
- 原始 grep 结果
- 完整测试日志
- 重复的文件内容
- 死胡同式的重试记录
我还觉得某些上下文可以设置生命周期或过期时间。
然后到了需要压缩的时候,你就更容易判断什么对 LLM 有用。
如果我们看看 Anthropic 关于长周期任务的资料,他们会说你需要想办法保留架构决策、未解决的 bug 和实现细节,这样压缩的时候才知道留什么。
LangChain 的自主压缩方案是让 Agent 自己决定什么时候压缩,而不是等上下文已经膨胀了才做。Anthropic 的方案应该是后者。
有意思的是,现在团队开始把压缩当作一个系统问题来评估了——用基准测试和 Agent 专用的策略,而不是当作一个通用的摘要技巧。
我们可以看一篇最近的论文来感受一下效果。Jia 等人的论文说,在 6 倍压缩下,token 预算减少了 51.8% 到 71.3%,同时在 SWE-bench Verified 上的问题解决率还提高了 5.0% 到 9.2%。
所以说这不仅是省钱的事,整体性能也会变好。
至于具体能省多少,构建好的上下文本身要花不少功夫,但清理垃圾大概能腾出 30% 到 70% 的上下文,对应的美元也就省了这么多。
举个例子,10K 的上下文窗口,如果你清理掉 30% 到 50%,跑 10 万次的话,大概能省 $1,500。如果是 40K 的上下文窗口,这个数字能到 $6,000。
不过要注意,如果你的 Agent 用的是很小很便宜的模型,压缩的成本可能反而更高。
话说回来,保持上下文干净的好处是:你不会像语义缓存或路由那样牺牲质量。做得好的话,是稳赚不赔的。
问题当然就是——做起来费劲。
最后说两句
好,这篇文章挺长的,讲了四种帮你砍 Agent token 成本的方法。
当然了,具体要看你的场景:
- 大系统提示词 + 循环调用 → 用 prompt caching
- 通用 Q&A 机器人要压成本 → 试语义缓存
- 既有简单问题又有复杂问题 → 测试路由
- 不想发没用的 token → 保持上下文干净
可能以后我会单独写一篇更偏经济学视角的短文,针对特定的使用场景来算账。
希望这篇对你有帮助。有什么想法欢迎交流。